Crawl tarafta SEO araçlarının özelliklerini karşılaştırdığımda hemen hemen birçoğu aynı özellikleri barındırıyor.
Low pagespeed, duplicate tags, title-desc h1, link deeph, redirect urls vs. vs. daha da uzatabilirim.
Her hangi bir crawl aracı default ayarları ile kullanıldığında pek efektif sonuçlar alınamayabiliyor.
Düşük otoriteli bir rakibin bile bu şekilde çalışmalar yürüttüğünü düşünürsek, daha fazla veri daha fazla analiz daha fazla anlamlı sonuçlara ihtiyacımız olacaktır.
Bunun için, crawlı daha efektif yapabilmek için XPath kullanımından bahsedeceğim.
Screaming Frog ve XPath ile Nasıl Daha Anlamlı Veriler Elde Edilir?
Örnekler vereyim;
1- Bu blogumda yayınladığım içeriklerin okuma sürelerini toplayabilirim.
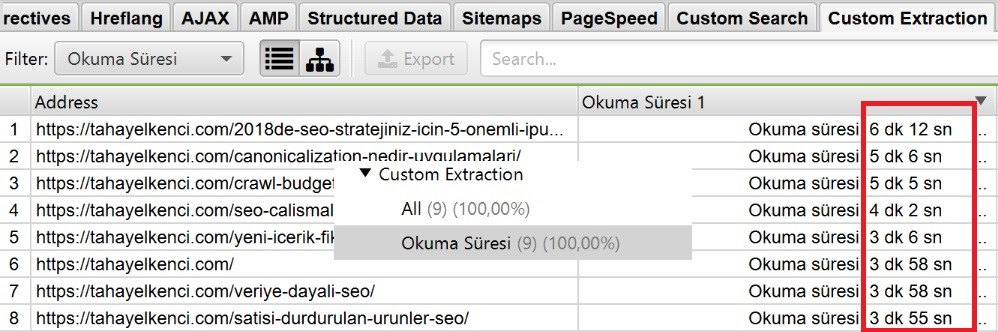
Screaming frog’da Xpath kullanımı kısmına geçmek için bu örnekleri atlayabilirsiniz.
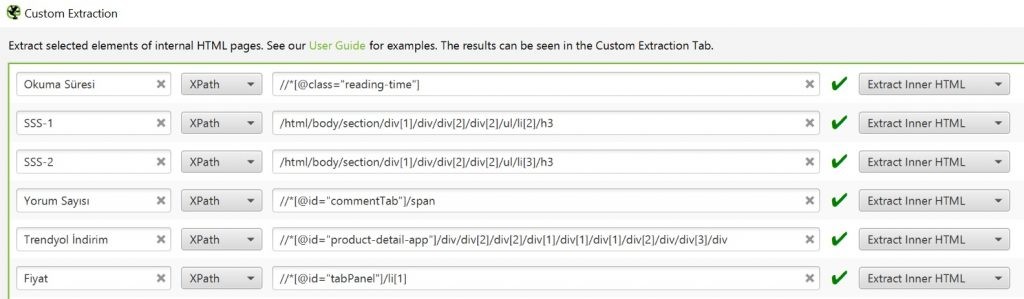
Veya o kısma geçmek için tıklayabilirsiniz.
2- Bitturk.com ‘un ürün sayfalarında bolca Sıkça Sorulan Sorular alanı mevcut. Siteyi crawl ederken tüm SSS sorularını öğrenmek için XPath kullanarak tüm soruları alabiliriz.
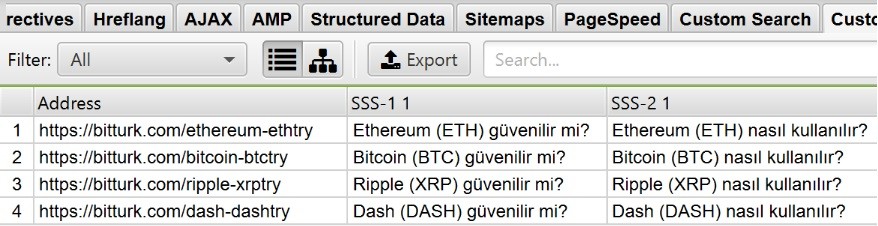
3- Elinizdeki bir ürün için landing page hazırlayacağımızı düşünelim.
Bu ürün için kullanıcılar en çok hangi soruları soruyor? En çok memnun kaldıkları yerler neresi? Şikayetleri neler? Gibi birçok sorunun cevabını bulmak ve sayfa içerisinde kullanıcı deneyimini geliştirmek adına ürün yorumlarını toplayabiliriz.
“Samsung galaxy note fe” ürünü için Hepsiburada’dan tüm yorumları alabiliriz.
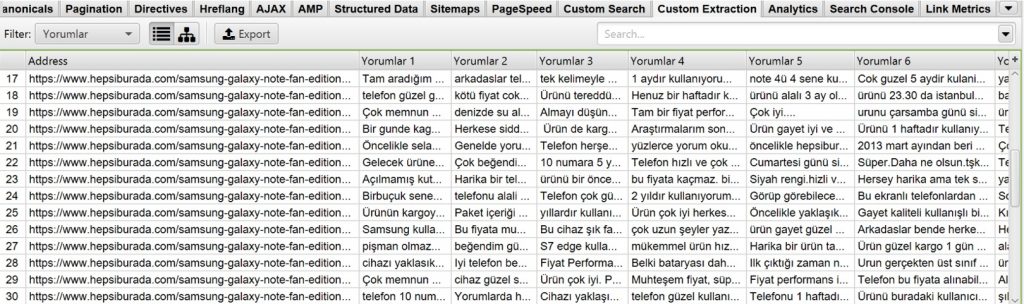
Bu yorumları anlamlandırmak için Excelde en çok tekrarlanan kelimeleri filtreleyebilir ve anlamlandırabiliriz.
Bu şekilde örnekleri fazlalaştırabiliriz fakat önemli olan ihtiyaç doğrultusunda hangi verilerin kullanılması gerektiği ve bu veriyi anlamlandırabilmek.
Birçok sayfa için ortak özellikleri belirleyip crawldan önce toola tanımlayarak crawl sonrası oluşacak verimizi büyütebiliriz.
Xpath kullanımına geçelim.
Önce toplayacağımız veri kaynağını inceleyelim. Bu ürün fiyatı olabilir, yorum sayısı olabilir, yorumlar olabilir vsvs. İhtiyaca göre belirlenebilir.
Ben ürüne ait tüm yorumları almak istiyorum.
Ürün yorumlarını barındıran sayfayı Chrome console ile inceleyebilirim.
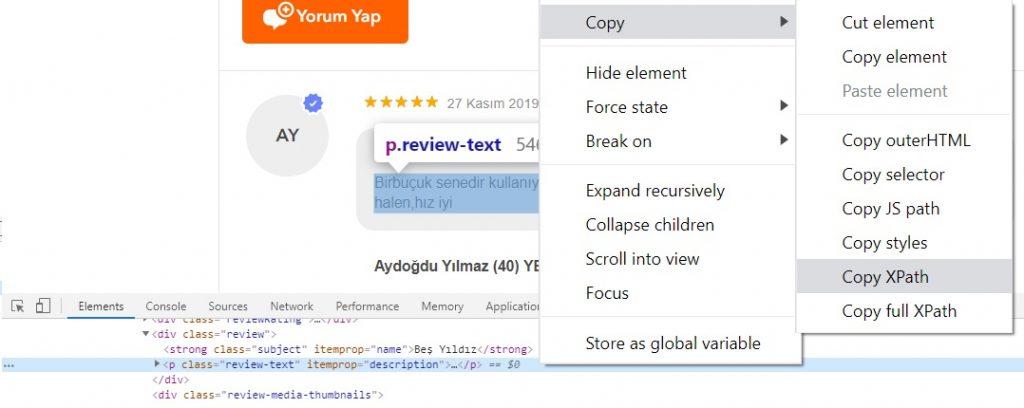
Yorum kısmına baktığımda alanın class’ı ”review-text” şeklinde. Bu classın XPath değerini almak için Chrome console kullanabiliriz ve üstteki görseldeki adımlarla kolayca değeri kopyalayabiliriz. Fakat Chrome console her zaman doğru değeri veremeyebiliyor.
Bu nedenle XPath’ı manuel oluşturmamız gerekebilir. ( //*[@class=”review-text”] şeklinde )
Veya alternatif olarak Chrome’da Scraper eklentisini kullanabiliriz.
XPath ile veri toplamayı Screaming Frog aracı üzerinden göstereceğim.
Crawl’a başlamadan önce bu işlemler için Config > Custom > Extraction alanından XPath bilgilerinin doğru şekilde doldurulması gerekiyor.
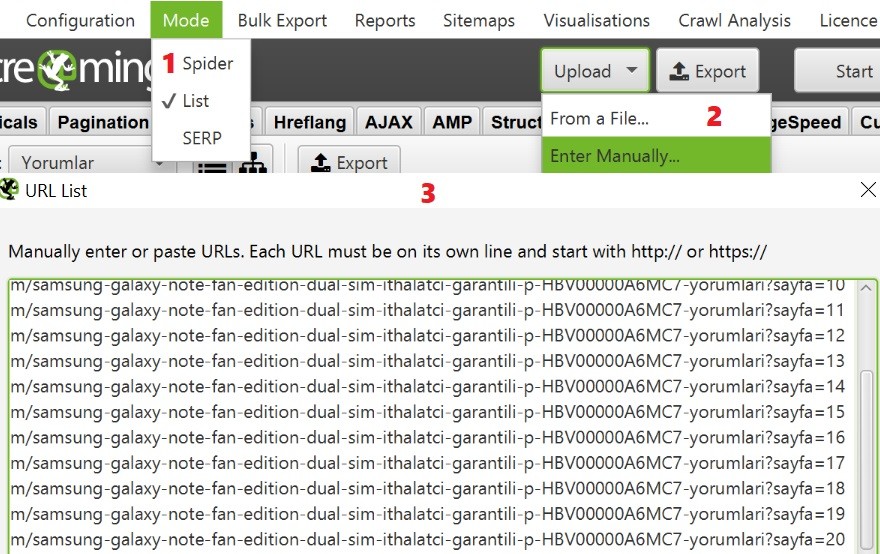
Sonrasında toplayacağım yorumlar sadece 1 ürün için geçerli olduğundan sadece ürün yorumu bulunduran sayfaları crawl edeceğim. Taranacak sayfa sayısı fazla ise Excel ile URL’leri çoğaltıp sonrasında Screaming Frog’da sadece belirli sayfaları tarayacağım.
Keyifli crawllar.